day5 analytics

timeline
may 2025 - august 2025
role
day5 analytics is a data-focused company. i joined the data and ai enablement team and worked on improving internal tooling and data platforms through applied engineering.
project 1: data api on analytics warehouse
i worked on two major projects during this internship.
project 1: data api on top of an analytics warehouse
laying the groundwork .....
most analytical systems that exist today are designed for analysts or folks who often work with data.
they assume users will write sql, understand schemas (star vs snowflake), and connect directly to a database.
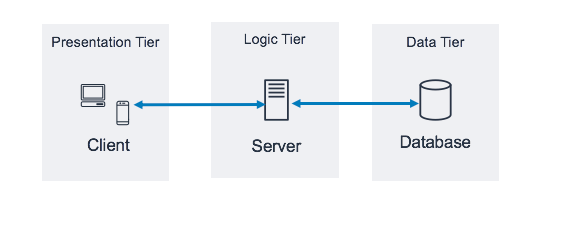
now think about frontend development for a second ...
well frontend development is largely built around api's, frontend frameworks & languages. frontend engineers call api's
to get data, save results, and perform other tasks. it is perfectly fine to issue multiple api requests to gather
data that might come together to form a simple webpage. an important thing to note is that in this style of frontend
engineering, we do not directly connect to a database, but rather interact with a middle "man" that converts our
questions into specific queries which then retrieve the data and return it in a formatted fashion.
this is known as three tier web applications.
now to what i worked on ....
instead of exposing data warehouse directly, i built a rest api that turns data into a service.
at a high level, this system introduces a clear separation between data storage and data consumption.
the warehouse remains an internal computational engine responsible for storing and processing large volumes of data.
on top of it is where our rest api sits, and it is the only interface that external consumers interact with.
clients make requests describing what they want and the api handles everything else.
this api plays several critical roles. first, it acts as a security boundary. consumers never receive direct access
to underlying data, which prevents misuse and allows access to be tightly controlled. second, it centralizes data and
transformations, ensuring all consumers see consistent outputs. lastly, it allows the data model to evolve without
breaking downstream applications. let's take a look at the architecture of this system.
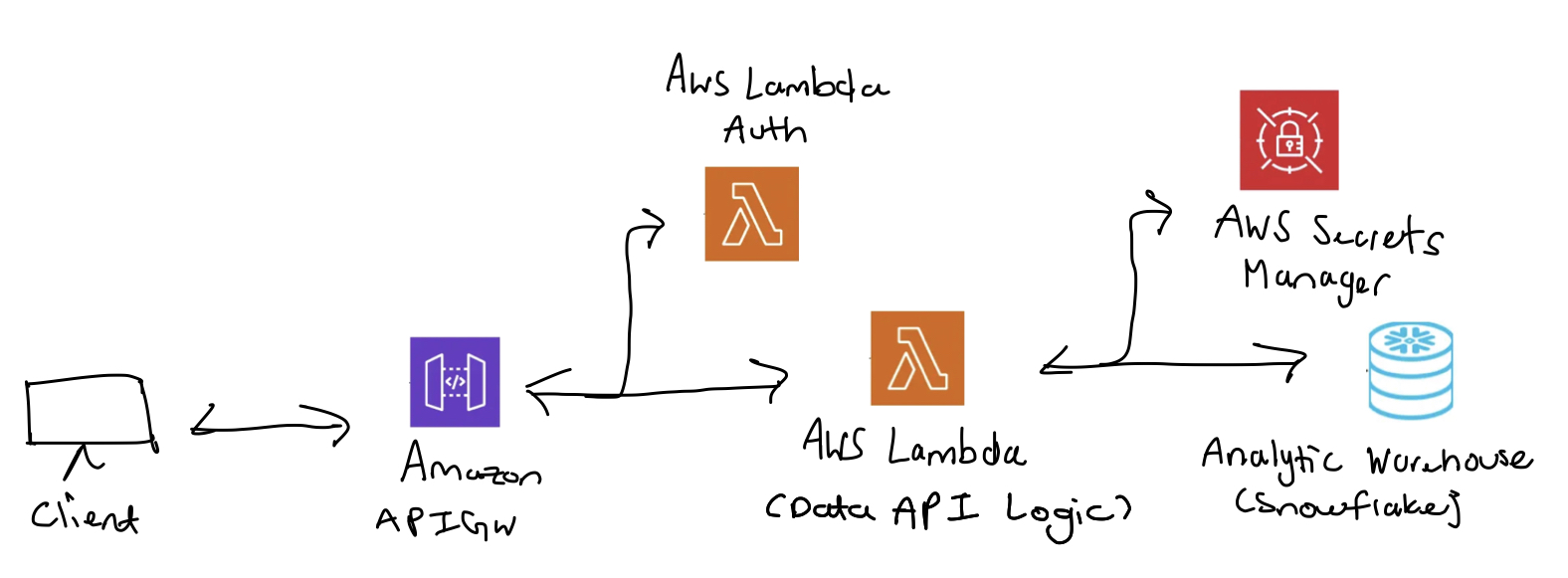
i mainly used aws services to build this system. amazon apigw is used for the http service while aws lambda handles
authentication for apigw endpoints and also serves as the data api logic layer. the data api logic layer translates
the http request into a snowflake query and returns the result. snowflake is where our data was primarily stored.
aws secrets manager was used to store application credentials for snowflake.
let's take a step back and look at the data api logic more fundamentally. this architecture works well,
but only if the rest api endpoints are designed with the nature of the data in mind. when working with a small,
well-understood dataset, endpoint design is straightforward. however, this approach does not scale to large or
unfamiliar datasets. in those cases, building endpoints around specific tables or use cases becomes tedious.
the key realization is that an api endpoint is not a table or a query, but a question that a system is allowed to ask.
so instead of designing endpoints for individual datasets, i built a generalized rest api layer that exposes
common analytical queries such as metrics, trends, and filtered summaries. this allows the same api structure
to work across different data domains while remaining flexible for downstream consumers like automation and ai agents.
i won't go into exact endpoint details because it's complicated (and partially confidential), but this is a solid summary
of what i worked on. overall, this project taught me a lot of software engineering fundamentals.
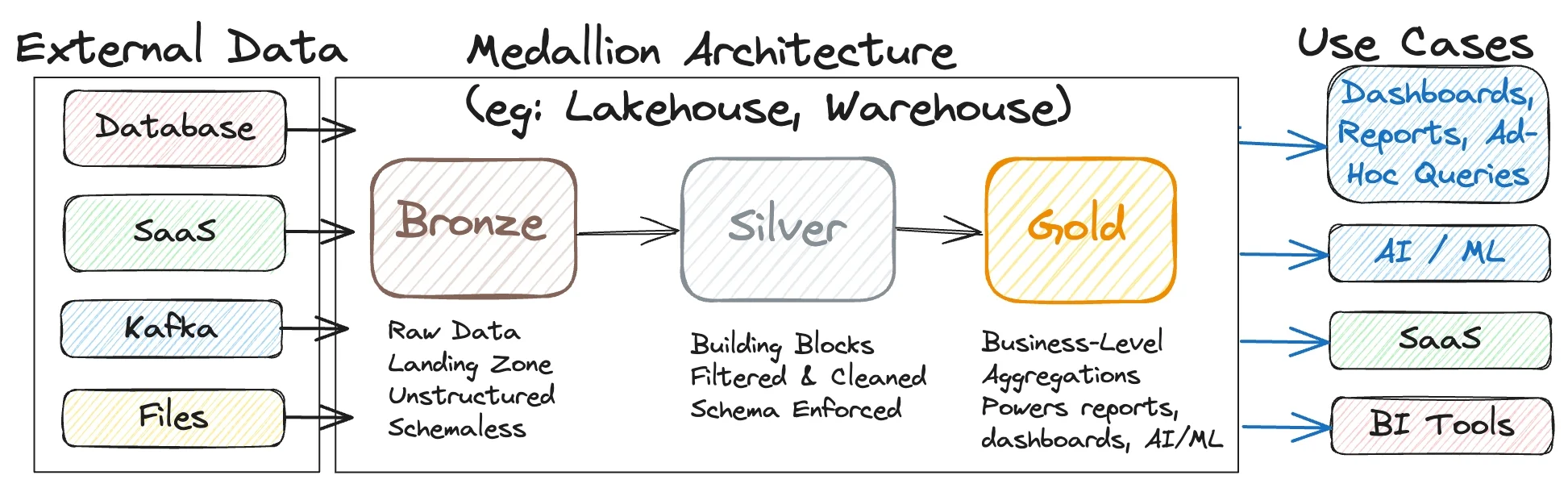
project 2: medallion migration
after working on exposing analytics through a governed data api, i shifted focus upstream to large-scale data ingestion.
this project focused on migrating and consolidating 200+ api endpoints into a unified platform using a medallion
architecture designed for long-term growth.
the bronze layer captured raw api responses exactly as received. with wide variation in response formats across
endpoints, a key part of this work was standardizing how json responses were stored and grouped.
endpoints were categorized by response shape and behavior, which allowed ingestion logic to be reused across similar
apis rather than rewritten per endpoint.
the silver layer handled normalization and structure. semi-structured json was parsed into consistent relational schemas,
with data quality checks, deduplication, and incremental load logic applied centrally.
by grouping endpoints with similar json structures, transformations could be metadata-driven instead of hardcoded.
the gold layer exposed business-ready datasets built around analytics use cases rather than source systems.
these tables were optimized for reporting, trend analysis, and semantic modeling, making them directly consumable
by bi tools, automation workflows, and ai agents.
a core design principle throughout the project was metadata-driven orchestration. ingestion and transformation behavior
was controlled through configuration rather than custom code, allowing new endpoints to be onboarded quickly while
maintaining consistency and reliability across the platform.